Building Effective Pen-testing Agents# Building Effective Pen-testing Agents After reading [Argus Red](https://www.argusred.com/cli)'s ["We post-trained a model that pen tests instead of refusing"](https://news.ycombinator.com/item?id=48609231) on HN last week, we figured it was time to share what we've learned at [Cecuro.ai](https://cecuro.ai/) about pen-testing agents, from building the best-performing agent on [EVMBench](https://openai.com/index/introducing-evmbench/) (OpenAI's smart-contract security benchmark). We don't agree that you need to fine-tune a model, but it does reduce how much context engineering you need. # TL;DR - The "off-the-shelf models refuse offensive work" claim is mostly wrong, from what we've seen. Across 10K+ agent transcripts we saw zero refusals. The refusal mostly comes from a separate, configurable content classifier and the system prompts, not the model itself (we run Azure-hosted GPT-5.4, DeepSeek-V4, GPT-5.2, GPT-5.3-Codex). - All the knowledge needed for pen-testing is already in the models. Context engineering is what unlocks it. A fine-tuned model makes the unlock easier, but it isn't needed. - Recall and performance are a numbers game. The median bug is found by six independent strategies in our system, and no single strategy finds more than 82% of the bugs we know are there. - The model often finds the bug, then talks itself out of reporting it. 25% of bugs lost after discovery are killed by an over-cautious agent. - Context engineering is the hard part on a large codebase. Even with a 1M-token window you should not fill it. Agents are far more effective under 200K tokens, and stuffing those 200K with the right information is the challenge. - The lever is breadth, not a bigger model. The same frontier models score 20-46% bare on this benchmark. You buy recall with more agents looking at more things, which is why cheap tokens beat model prestige. 100 DeepSeek V4 agents > 2 passes of GPT-5.5. Same pattern when you control for model knowledge cutoff. --- The rest of this post is the long version: five things 10K agent transcripts from our EVMBench runs revealed. We score [91.45% on EVMBench](https://cecuro.ai/benchmarks/), first on the leaderboard and ahead of the next best at 78.6%, and we do it on a stock Azure GPT-5.4 deployment with no fine-tuning, no offensive post-training, and nothing done to the model's refusals. ## 1. The model doesn't refuse. The classifier in front of it does. Argus Red's premise is that public models are "explicitly guard-railed so that they refuse offensive tasks," and that wrapper tools "inherit its refusals." We looked for those refusals in our own data. We grepped all 10K+ transcripts for every refusal pattern we could think of: "I can't help," "as an AI," "against policy," "no," "hacking," ethical hedging, the lot. Genuine refusals: zero. The only regex hits were findings that happened to use the words "cannot" and "unable" in ordinary technical sentences. Meanwhile the same model happily writes things like "attacker can keep hooks permanently dusted to DoS contract-based position managers." The reason is that on the public APIs the refusal usually isn't the model. It's a separate moderation classifier sitting in front of it, or the [system prompts](https://github.com/asgeirtj/system_prompts_leaks/blob/main/Anthropic/claude-fable-5.md?plain=1#L64) used in the harness. [OpenAI's moderation endpoint](https://developers.openai.com/api/docs/guides/moderation) is its own model. [Azure's content filter](https://learn.microsoft.com/en-us/azure/ai-foundry/openai/how-to/content-filters?view=foundry-classic) is, in their words, "an ensemble of multi-class classification models" running alongside the core model. You can tune it by severity, and with approval, turn it off. That's the gate. Run a deployment without the aggressive filter, frame the task as the audit it is, and the base model does offensive analysis all day. That said, the full chain-of-thought is encrypted, so we only see summarised outputs, and none of them refused. As seen below, the default filters of Azure are quite strict  ## 2. Recall is a numbers game, not a genius game Take one case: [Size](https://github.com/evmbench-org/2024-06-size), a lending protocol in the benchmark. All four of its high-severity bugs live in roughly the same place, the liquidation path across `Liquidate.sol` and the accounting library, so it's a clean test of how reliably the system reads one important file. Take the first one, where the liquidator-profit math is wrong, so rational liquidators never show up. Only 8% of the agents that read this file reported the bug. The other agents read the exact same code and moved on. The 8% that caught it weren't running the same playbook either; they came in under different security lenses, which is the name of the game. You catch the bug because a hundred agents each take a different swing, not because any one is brilliant. ## 3. The model finds the bug, then talks itself out of it The agent rarely fails to find the bug. It finds it, writes out the vulnerable code path, then convinces itself not to report it. This happens before any explicit gate, inside the model's own reasoning, where it quietly downgrades its own finding to "probably intended" and moves on. This often happens as context windows grow past 100K tokens, but we have not done research into it yet. ## 4. Context engineering is the whole game on a large codebase You cannot solve recall by handing one agent a million-token window and the entire repo. Long context degrades well before the advertised limit. Fable 5 is much better at this, but [Context Rot](https://www.trychroma.com/research/context-rot) is a thing for all LLMs, and performance "grows increasingly unreliable as input length grows," even on simple tasks. Usable attention falls off long before you hit the wall, filling the context window is often a big cost driver, and it degrades performance. The [Agent Skills](https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills) progressive-disclosure pattern (see a capability's name first, load the full instructions only when relevant, pull referenced files only when needed) is very helpful here, and we use it extensively. That, along with agents communicating and sharing what they learn between them, does a lot of the work. Argus Red built theirs in the same shape. Their post describes "a multi-agent swarm: an orchestrator splits the job across subagents running in parallel, each owning a slice, then synthesising one report." We agree completely that this is what works, but some things need to be deterministic, and a pipeline is better at ensuring coverage than a fully agentic setup (we also tried that, with [PI](https://github.com/earendil-works/pi) and 5x nested sub-agents). ## 5. You buy recall with agents, not with a bigger model This is the lever the benchmark makes obvious. On EVMBench the same frontier models score [20-46% on their own](https://chainwire.org/2026/04/16/ai-audit-firm-cecuro-outperforms-nearest-rival-by-2x-on-openai-smart-contract-exploit-benchmark/). Wrapped in this orchestration, the same class of model reaches 91%. The model isn't the differentiator. The number of independent looks is. 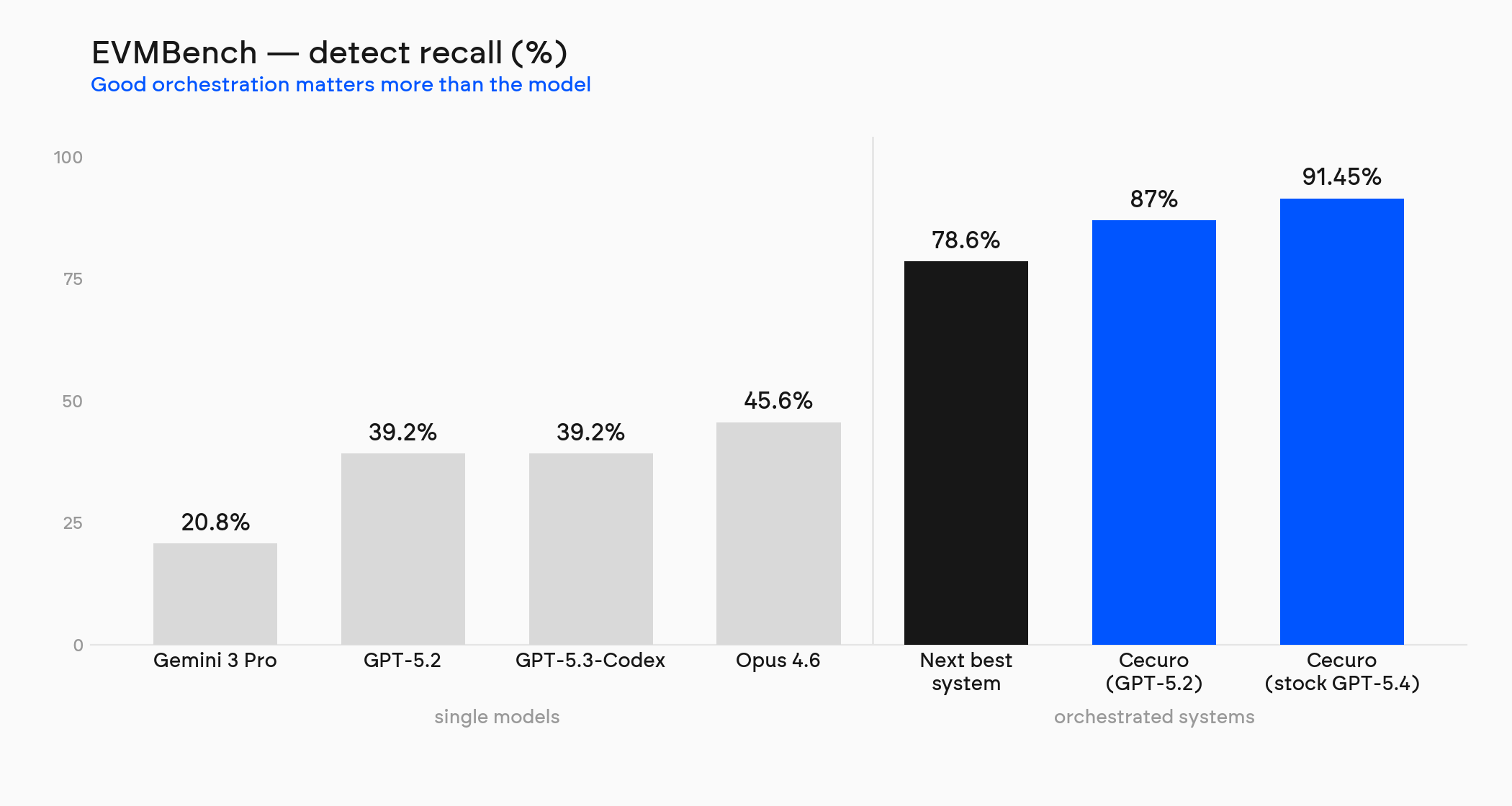 A better model helps, just not the way people think. The stronger the base model, the less hand-holding it needs: fewer instructions, wider coverage on its own, more intuitive about where a bug hides. It's simply easier to work with. But "easier to get the findings out" is not "the only way to get them out." With enough context engineering you can pull the same bugs from a cheaper model; the better model just surfaces them with less effort. Model quality is a convenience lever, not a capability ceiling. Paying a premium for it only makes sense if you can't engineer your way there, or if it's the cheaper or better strategic choice. That's why a model like [DeepSeek V4](https://tokenmix.ai/blog/gpt-5-5-vs-deepseek-v4-closed-vs-open-2026), at a fraction of frontier pricing, makes so much sense: 100 DeepSeek V4 agents covering 100 angles beat two passes of a premium model for the same dollars. A stock frontier model already [placed 25th in an elite CTF](https://arxiv.org/abs/2511.04860), between the world's #3 and #7 human teams, so the capability floor was never the constraint. Price per token is. ## Where this goes Agents are getting scary good, but you don't need Fable 5 for this. You can outperform it already. We built [Cecuro.ai](https://cecuro.ai/) over the last year, and the performance you can squeeze out of commonly available models competes with the bigger general models when you put in domain knowledge and good context engineering. Systems are only becoming more at risk with every model release, as the price of LLMs comes down and their intelligence goes up. If you're shipping smart contracts, we highly recommend you **[Run your contracts through Cecuro](https://app.cecuro.ai)** and get a full audit back in hours.