Cecuro Leads OpenAI's EVMBench: Detection on Smart Contract Exploits**TL;DR** - **Cecuro scored 87.17% on EVMBench**, identifying 102 of 117 high-severity vulnerabilities across 40 real-world audit cases - **Nearly double the next-best system**: Claude Opus 4.6 scored 45.6%, GPT-5.3-Codex scored 39.2%, Gemini 3 Pro scored 20.8% - **EVMBench is the new industry standard** for measuring AI smart contract security capabilities, created by OpenAI, Paradigm, and OtterSec - **General-purpose AI is not enough**: Every major AI lab was represented. None came close to a purpose-built security system - **The offense is accelerating**: AI exploit capability doubles every 1.3 months at $1.22 per contract. Defense needs to keep pace - **Consistent results**: Cecuro previously achieved 92% detection on our own benchmark of 90 real-world exploited contracts ($228M in losses) [Start your AI-powered audit in hours, not weeks ->](https://app.cecuro.ai) --- ## What Is EVMBench? On February 18, 2026, researchers from OpenAI, Paradigm, and OtterSec released EVMBench, an open-source benchmark designed to evaluate how well AI agents perform on smart contract security tasks. Within days, it established itself as the industry standard for measuring AI security capabilities in the EVM ecosystem. The benchmark contains 117 curated high-severity findings drawn from 40 real-world audit cases, primarily sourced from competitive audit platforms like Code4rena. These are not synthetic test cases. They are real vulnerabilities that were independently discovered and confirmed through professional audit processes. EVMBench evaluates AI systems on three distinct tasks: | Task | What It Measures | Description | | ----------- | -------------------------------------------- | ----------------------------------------------------------------------- | | **Detect** | Can the AI find the vulnerability? | Given smart contract source code, identify high-severity security flaws | | **Exploit** | Can the AI write a working proof of concept? | Given a known vulnerability, write code that exploits it end-to-end | | **Patch** | Can the AI fix the vulnerability? | Given a known vulnerability, produce a correct remediation | Each task tests a different aspect of AI security capability. The detect task is the hardest and most relevant for defensive applications, because it requires the AI to discover vulnerabilities without knowing they exist. There is no feedback signal, no known target. The agent must analyze code, form hypotheses, and correctly identify issues through reasoning alone. The benchmark uses containerized environments with deterministic EVM replay and automated scoring. Every finding is a high-severity vulnerability independently confirmed through competitive audit processes. Models are evaluated with simple, standardized system prompts across leading AI coding tools, providing a fair baseline for comparison. ### Why EVMBench Matters Before EVMBench, there was no standardized way to compare AI systems on smart contract security. Individual benchmarks (including our own) provided useful data, but the industry lacked a widely adopted, third-party evaluation framework. EVMBench fills that gap. It was created by three organizations with deep credibility in AI (OpenAI), blockchain infrastructure (Paradigm), and smart contract security (OtterSec). The findings are sourced from competitive audits, which means they represent the kinds of complex, high-impact vulnerabilities that actually cause losses in production. For DeFi teams choosing security tooling, EVMBench provides an objective answer to a critical question: how well does this AI system actually find vulnerabilities? --- ## The Results: Specialized AI Dominates 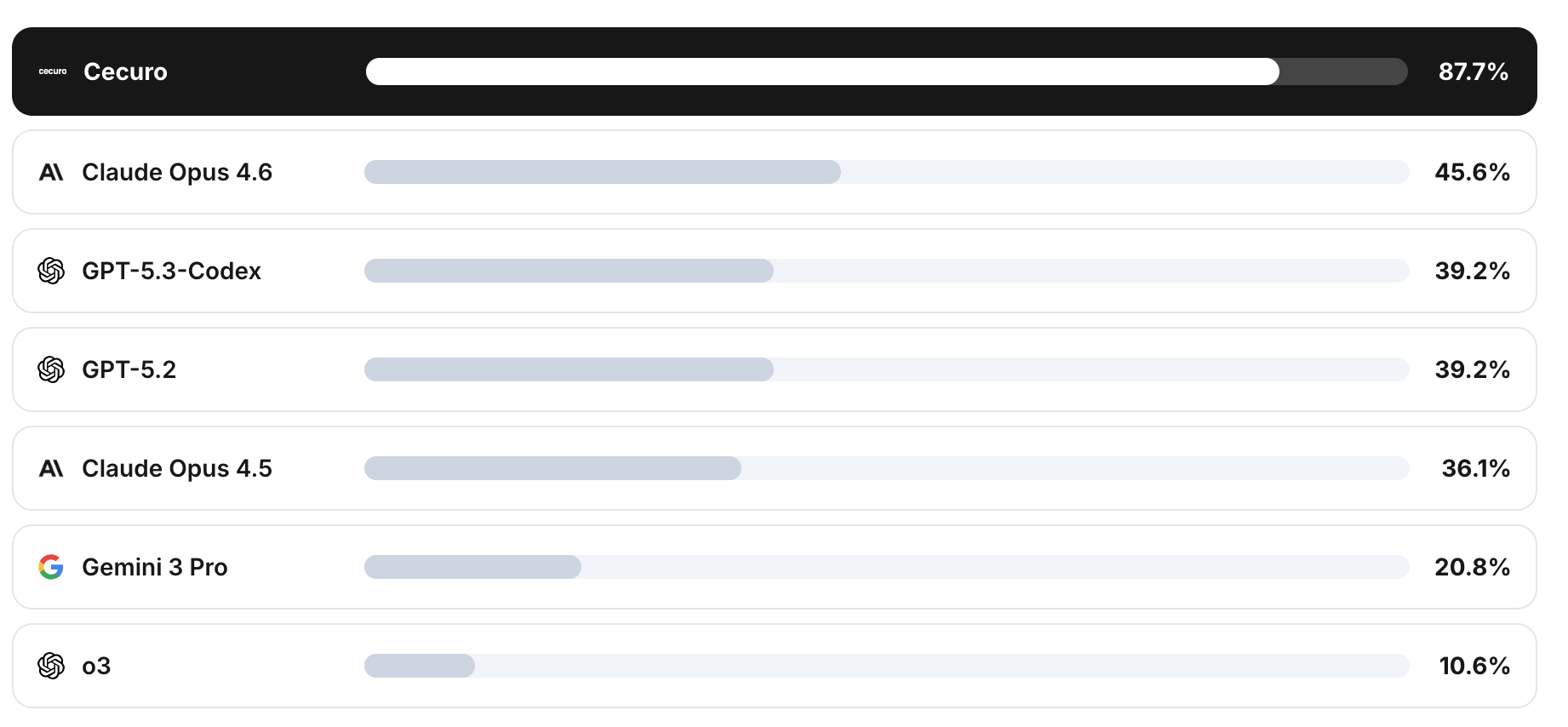 Cecuro's multi-agent security system achieved an **87.17% recall** on the EVMBench detect task, identifying **102 of 117 high-severity vulnerabilities** across all 40 audit cases. The next-best system, Anthropic's Claude Opus 4.6, scored 45.6%. Here are the full results: | System | Detection Rate | Notes | | --------------- | -------------- | ------------------------------------------ | | **Cecuro** | **87.17%** | Multi-agent, purpose-built security system | | Claude Opus 4.6 | 45.6% | Anthropic's most capable model | | GPT-5.3-Codex | 39.2% | OpenAI's coding-optimized model | | GPT-5.2 | 39.2% | OpenAI's general flagship model | | Claude Opus 4.5 | 36.1% | Previous Anthropic flagship | | Gemini 3 Pro | 20.8% | Google's frontier model | | o3 | 10.6% | OpenAI's reasoning model | Every major AI lab was represented. Cecuro's detection rate was nearly double Claude Opus 4.6, more than double GPT-5.3-Codex and GPT-5.2, and more than four times Gemini 3 Pro. These are not marginal differences. Cecuro detected 102 vulnerabilities. The best general-purpose model found 55. That is 46 additional high-severity findings that a team relying on a frontier AI model alone would have missed. ### What the Gap Means in Practice Consider a DeFi protocol preparing for launch. The team runs their smart contract code through a frontier AI model for a security review. The model finds roughly 40% of high-severity vulnerabilities. The team fixes those issues and deploys, feeling confident. But 60% of critical vulnerabilities remain undetected. Those are the ones attackers find. With Cecuro, that same team catches 87.17% of high-severity issues before deployment. The attack surface shrinks dramatically. The vulnerabilities that remain are the truly novel edge cases that challenge any analysis approach, human or AI. The difference between 40% detection and 87.17% detection is not incremental. It is the difference between deploying with known blind spots and deploying with genuine coverage. [Get Cecuro-level detection for your protocol ->](https://app.cecuro.ai) --- ## Why Specialized AI Beats General-Purpose AI The EVMBench results raise an obvious question: why does a purpose-built system outperform models that are, by most measures, more generally capable? Claude Opus 4.6, GPT-5.3-Codex, and Gemini 3 Pro are extraordinary AI systems. They can write code, solve math problems, analyze legal documents, and generate creative content at near-human or superhuman levels. And yet, on smart contract vulnerability detection, they score between 10% and 46%. The answer lies in what vulnerability detection actually requires. ### Smart Contract Security Is a Specialized Domain Finding vulnerabilities in smart contracts is not a general reasoning problem. It requires deep domain knowledge that general-purpose models possess only partially. When a security expert audits a lending protocol, they bring specific knowledge about how Compound-style interest rate models accumulate rounding errors, how Uniswap V2/V3 pools calculate prices and how those prices can be manipulated within a single transaction, how flash loans enable attack sequences that would be impossible with organic capital, and how cross-contract callbacks create reentrancy paths that only surface under specific liquidity conditions. General-purpose AI models have been trained on code that includes smart contracts, and they understand Solidity syntax, common patterns, and basic security concepts. But understanding syntax is not the same as understanding the economic attack surface of a DeFi protocol. ### The Architecture Gap The performance gap is not about raw intelligence. It is about how that intelligence is directed and structured. A general-purpose model given a smart contract to review will typically scan the code linearly, flag patterns it recognizes as potentially dangerous, and produce a report. This approach catches the obvious issues: missing access control, unprotected external calls, basic reentrancy patterns. But the high-severity vulnerabilities in EVMBench are not obvious. They involve multi-step reasoning across contracts, understanding of protocol economics, and recognition that patterns appearing safe in isolation become exploitable under specific market conditions. Cecuro's multi-agent system approaches the problem differently. Rather than a single model making a single pass, multiple specialized agents analyze the code from different angles. One agent focuses on access control patterns. Another analyzes token flow and accounting logic. Another evaluates oracle dependencies and price manipulation vectors. A coordination layer synthesizes findings, identifies conflicts, and directs deeper investigation where initial analysis raises questions. This architecture mirrors how the best human audit teams work: specialists collaborating, each bringing domain expertise to a shared review. The difference is speed. What takes a human team weeks takes Cecuro's agents hours. ### A Concrete Example: Why General Models Miss DeFi Vulnerabilities Consider a vulnerability pattern that EVMBench tests: a lending protocol where the liquidation threshold calculation uses a stale price oracle, creating a window where an attacker can manipulate prices to trigger liquidations at favorable rates. A general-purpose model reviewing this code might: 1. Check that the oracle is called correctly (it is) 2. Verify that access controls are in place (they are) 3. Confirm that math operations don't overflow (they don't) 4. Report: "No critical vulnerabilities found" A specialized security agent reviewing the same code would: 1. Identify the oracle dependency and check staleness handling 2. Analyze the liquidation math to understand profit conditions for an attacker 3. Evaluate whether flash loans could amplify the attack 4. Check if the oracle price can be influenced within the same transaction 5. Calculate the minimum price movement needed to trigger profitable liquidations 6. Report: "Critical: Liquidation threshold can be exploited via oracle manipulation in combination with flash loan. Estimated impact: [X]" The specialized agent catches the vulnerability because it knows what to look for. It understands DeFi-specific attack patterns, and its analysis methodology is built around systematically testing for them. ```solidity // ❌ VULNERABLE: Liquidation uses spot price without manipulation protection function liquidate(address borrower) external { uint256 collateralValue = oracle.getPrice(collateralToken) * collateralBalance; uint256 debtValue = oracle.getPrice(debtToken) * debtBalance; // No staleness check on oracle price // No deviation check against secondary sources // No flash loan guard on liquidation path require(collateralValue < debtValue * liquidationThreshold / 1e18, "Position healthy"); // Execute liquidation... } ``` ```solidity // ✅ SAFE: Multi-layered protection against oracle manipulation function liquidate(address borrower) external nonReentrant { // Staleness check (uint256 price, uint256 updatedAt) = oracle.getLatestPrice(collateralToken); require(block.timestamp - updatedAt < MAX_ORACLE_STALENESS, "Stale oracle"); // Deviation check against secondary source uint256 twapPrice = twapOracle.getPrice(collateralToken); uint256 deviation = abs(price - twapPrice) * 1e18 / twapPrice; require(deviation < MAX_PRICE_DEVIATION, "Price deviation too high"); // Sanity bounds require(price > MIN_PRICE && price < MAX_PRICE, "Price out of bounds"); uint256 collateralValue = price * collateralBalance; uint256 debtValue = oracle.getPrice(debtToken) * debtBalance; require(collateralValue < debtValue * liquidationThreshold / 1e18, "Position healthy"); // Execute liquidation with additional checks... } ``` This kind of analysis requires understanding the economic context of the code. A general-purpose model sees syntax. A specialized agent sees attack surfaces. --- ## AI Exploit Capability Is Accelerating The EVMBench results do not exist in a vacuum. They arrive alongside growing evidence that AI is fundamentally changing the economics of smart contract exploitation. ### The Numbers Anthropic's SCONE-bench research, published in December 2025, found two alarming statistics: 1. **The average cost of an AI-powered exploit scan has fallen to $1.22 per contract** 2. **Offensive AI capability is doubling approximately every 1.3 months** On EVMBench itself, OpenAI's GPT-5.3-Codex achieved a **72.2% success rate** executing end-to-end exploits against known vulnerable contracts. That means a general-purpose AI model, without any specialized security training, can successfully exploit nearly three out of four known vulnerabilities when given the source code. With $3.4 billion stolen from blockchain platforms in 2025, the gap between offensive and defensive AI capability continues to widen. ### The Attacker's Math At $1.22 per contract, a motivated adversary can scan thousands of smart contracts for under $2,000. The tooling is commercially available. The barrier to entry is effectively zero for anyone with API access and basic domain knowledge. Two years ago, exploiting a smart contract required deep technical expertise, custom tooling, and significant time investment. That barrier has collapsed. The cost of offense has dropped from months of human effort to minutes of computation, while the success rate has climbed to 72%. This creates a structural problem for the industry. Attackers benefit from AI improvements automatically, because exploitation is self-verifying: funds move or they don't. Defense requires deliberate investment in purpose-built systems, because detection demands structured investigation, false positive filtering, and domain-specific reasoning that general-purpose models do not perform on their own. ### What This Means for Every Smart Contract Project The threat model has changed. Projects are no longer defending against skilled individuals spending weeks researching a target. They are defending against automated systems that can scan thousands of contracts in hours at negligible cost, and that improve measurably every month. The question is no longer whether AI changes a project's security posture. It already has. The question is whether the project has built the defense side to match. --- ## Consistent Results Across Benchmarks The EVMBench results are consistent with Cecuro's earlier benchmark, which was [covered by CoinDesk](https://www.coindesk.com/tech/2026/02/19/this-ai-security-bot-says-it-could-have-prevented-usd97m-in-defi-hacks) and evaluated 90 real-world exploited contracts representing $228 million in actual losses. | Benchmark | Cecuro Detection Rate | Best General-Purpose AI | Performance Gap | | ------------------------------------------------------------------ | --------------------- | ----------------------- | --------------- | | **EVMBench (OpenAI)** (117 findings, 40 audit cases) | 87.17% | 45.6% (Claude Opus 4.6) | ~2x | | **SCONE-bench (Anthropic)** (90 exploited contracts, $228M losses) | 92% | 34% (GPT-5.1 baseline) | ~2.7x | The consistency matters. A single benchmark can always be questioned. Two independent evaluations, using different datasets, different methodologies, and different comparison baselines, pointing to the same conclusion is much harder to dismiss. In both cases, Cecuro's specialized system detected roughly 2-3x more vulnerabilities than the best general-purpose AI system available. In both cases, the performance gap was most pronounced on high-value, high-complexity vulnerabilities: the ones that actually drive real-world losses. The Cecuro benchmark additionally measured the dollar value of vulnerabilities detected. Cecuro's system covered $96.8 million in exploitable value compared to $7.5 million for the general-purpose baseline. That is a 13x gap in protectable value, because the hardest vulnerabilities to detect are also the ones with the highest potential impact. --- ## What This Means for DeFi Teams ### If You're Choosing Security Tooling The EVMBench results provide a clear, third-party answer to the question of whether general-purpose AI is sufficient for smart contract security. It is not. The best general-purpose model found fewer than half the high-severity vulnerabilities in the benchmark. A purpose-built system found 87.17%. This does not mean general-purpose AI is useless for security. A 40% detection rate is far better than no review at all, and frontier models are improving rapidly. But for production smart contracts managing real value, relying on a general-purpose model alone leaves a significant portion of the attack surface unexamined. ### If You're Using AI to Write Smart Contracts The Moonwell exploit in February demonstrated what happens when AI-generated code deploys without adequate security review. AI tools accelerate development dramatically, but the code they produce contains the same categories of vulnerabilities as human-written code. AI-powered auditing matches the speed of AI-assisted development. If your development cycle runs in days, your security review should too. | Development Approach | Traditional Audit | AI-Powered Audit (Cecuro) | | ------------------------- | ------------------------------------ | -------------------------- | | AI-assisted coding (days) | Weeks to schedule, weeks to complete | Hours | | Manual coding (weeks) | Weeks to schedule, weeks to complete | Hours | | Continuous deployment | One-time snapshot | Can audit every deployment | | Pre-launch timeline | 4-8 weeks minimum | Same day | ### If You're Building on Any Chain EVMBench specifically tests EVM smart contracts, but the underlying principle applies across all blockchain ecosystems. Specialized AI security agents outperform general-purpose models because they bring domain-specific knowledge, structured methodology, and multi-pass analysis strategies that general models lack. Cecuro supports all chains and smart contract languages. The same architectural advantages that produce 87.17% detection on EVM contracts apply to Solana programs, Move contracts, and every other smart contract platform. --- ## The Benchmark Details For teams evaluating these results, here are the specifics of how EVMBench works. ### Dataset 117 high-severity findings from 40 audit cases, sourced primarily from competitive audit platforms (Code4rena). Each finding was independently confirmed through the competitive audit process, ensuring ground truth quality. ### Methodology EVMBench uses containerized environments with deterministic EVM replay. Each AI system receives the smart contract source code and a simple, standardized system prompt. The benchmark evaluates leading AI coding tools (Codex, Claude Code, etc.) rather than raw model API calls, testing the systems as developers would actually use them. Results report the best variant per model family, providing a fair comparison that accounts for differences in how each model is accessed. ### Scoring For the detect task, scoring is binary: either the system correctly identified the vulnerability or it did not. This strict scoring means partial credit is not awarded for findings that are close but do not match the specific vulnerability. ### What Cecuro's 87.17% Means Of the 117 high-severity findings in the benchmark: - **102 were correctly detected** by Cecuro's multi-agent system - **19 were missed** The 19 missed findings represent the frontier of current AI security capability. These are likely the most novel or structurally unusual vulnerabilities in the dataset, the cases where even domain-specific knowledge and structured methodology reach their limits. No security system, human or AI, achieves 100% detection. But every percentage point matters when the alternative is a multi-million dollar exploit. Cecuro keeps getting better, but is at current point in the the leading AI smart contract audit platform in the world. --- ## Looking Ahead EVMBench represents the beginning of standardized evaluation for AI smart contract security, not the end. As the benchmark matures and the community adopts it, we expect it to drive rapid improvement across the industry. Several dynamics are worth watching: **General-purpose models will improve.** Foundation model capabilities are advancing rapidly, and future versions of Claude, GPT, and Gemini will likely score higher on EVMBench. This is a good thing for the ecosystem. **The bar will rise.** As baseline AI security capability improves, EVMBench may need to expand to include harder vulnerabilities, more complex multi-contract interactions, and cross-chain scenarios. The benchmark should evolve with the threat landscape. **Specialization will continue to matter.** Even as general-purpose models improve, we believe the performance gap between specialized and general systems will persist. The domain knowledge required for smart contract security is deep enough that purpose-built systems will maintain a structural advantage, just as medical AI systems outperform general models on diagnostic tasks despite using smaller base models. **Offensive capability will keep accelerating.** The 72.2% exploit success rate and $1.22 cost per contract are today's numbers. In six months, they will be significantly more capable and cheaper. Defense must evolve in lockstep. --- ## Conclusion EVMBench gives the industry something it has needed: an objective, third-party benchmark for AI smart contract security. The results are clear. General-purpose AI models detect between 10% and 46% of high-severity vulnerabilities. Cecuro's purpose-built security system detects 87.17%. The performance gap is not about model size or raw intelligence. It comes from architectural specialization: domain-specific knowledge, structured multi-agent analysis, and methodology built around the specific patterns that cause real-world losses. With AI exploit capability doubling every 1.3 months and the cost per scan at $1.22, the security landscape is shifting faster than most projects realize. Automated attackers can now scan thousands of contracts for pocket change, using commercially available tools. The projects that survive this environment will be the ones that match offensive AI capability with equally capable defensive tooling. **Industry-leading 87.7% detection. Hours, not weeks. A fraction of the cost.** [Start your audit now ->](https://app.cecuro.ai) --- ## References (1) OpenAI, Paradigm, and OtterSec. "EVMBench: Evaluating Frontier AI on EVM Smart Contract Exploitation." February 2026. Available at: [https://cdn.openai.com/evmbench/evmbench.pdf](https://cdn.openai.com/evmbench/evmbench.pdf) (2) Anthropic Red Team. "Smart Contract Security Research." December 2025. Available at: [https://red.anthropic.com/2025/smart-contracts/](https://red.anthropic.com/2025/smart-contracts/) (3) Cecuro. "Benchmark: $97M in DeFi Exploits Preventable by Specialized AI." February 2026. Available at: [https://cecuro.ai/blog/97m-defi-exploits-preventable-specialized-ai](https://cecuro.ai/blog/97m-defi-exploits-preventable-specialized-ai) (4) CoinDesk. "This AI Security Bot Says It Could Have Prevented $97M in DeFi Hacks." February 2026. Available at: [https://www.coindesk.com/tech/2026/02/19/this-ai-security-bot-says-it-could-have-prevented-usd97m-in-defi-hacks](https://www.coindesk.com/tech/2026/02/19/this-ai-security-bot-says-it-could-have-prevented-usd97m-in-defi-hacks) (5) Chainalysis. "Crypto Hacking Hits $3.4B in 2025." Available at: [https://www.chainalysis.com/blog/crypto-hacking-stolen-funds-2026/](https://www.chainalysis.com/blog/crypto-hacking-stolen-funds-2026/)