We Entered 3 Audit Competitions with Claude Code. 0% Accuracy, 93 False Positives.# TL;DR - **93 findings generated across 3 competitive audits (Sherlock + Code4rena), 0 valid.** Sui Move and Solidity, same result - Our best finding survived validation by 5 separate AI agents — then died when a human provided one arithmetic counter-argument - The core problem: **no environment feedback**. Exploit benchmarks (55-72% success) give AI a test suite. Raw finding generation gives it nothing to check against - This post is about baseline AI without specialized tooling. The harness matters — this is what happens without one - At [Cecuro](https://cecuro.ai), we continuously benchmark leading general-purpose AI tools — Claude Code, Codex, Gemini — for security auditing. This is the latest round. Same methodology, repeated as models improve --- ## 1) The Benchmark Gap AI models are getting genuinely good at smart contract security, at least in specific, well-scoped settings. Anthropic's SCONE-bench[^scone] showed models exploiting smart contracts at a 55.8% success rate, a large jump from prior years. OpenAI and Paradigm's EVMbench[^evmbench] reported GPT-5.3-Codex achieving 72.2% on known vulnerabilities in the exploit category of the benchmark. But those benchmarks share a key property: **the AI gets feedback**. Write an exploit, run it, see if the funds move. The environment tells you whether you're right. Real auditing has no such loop — you're reading 10,000 lines of code asking "is there anything wrong here?" and the only feedback is your own reasoning. We wanted to see how baseline AI performs in that setting. We ran Claude Code — one of several tools in our ongoing benchmark series — with no custom tooling, no specialized prompts, just the standard agentic coding tool with parallel subagents, on three competitive audit contests: - **[Current Finance](https://audits.sherlock.xyz/)**: Compound-style lending protocol on Sui Move, ~10,500 lines. Sherlock contest. - **[Brix Money](https://code4rena.com/)**: Turkish Lira stablecoin (iTRY/wiTRY) with LayerZero cross-chain. Code4rena contest. - **[Merkl Protocol](https://code4rena.com/)**: Merkle-tree reward distribution, just 604 nSLOC. Code4rena contest. Different platforms, different architectures, same baseline AI pipeline. The combined result: ``` 93 initial findings across 3 audits → 0 valid vulnerabilities submitted False positive rate: 100% ``` --- ## 2) How We Approached It and What Happened ### The validation funnel Every finding went through a multi-stage validation pipeline. The funnel below shows Current Finance (our most thorough run): 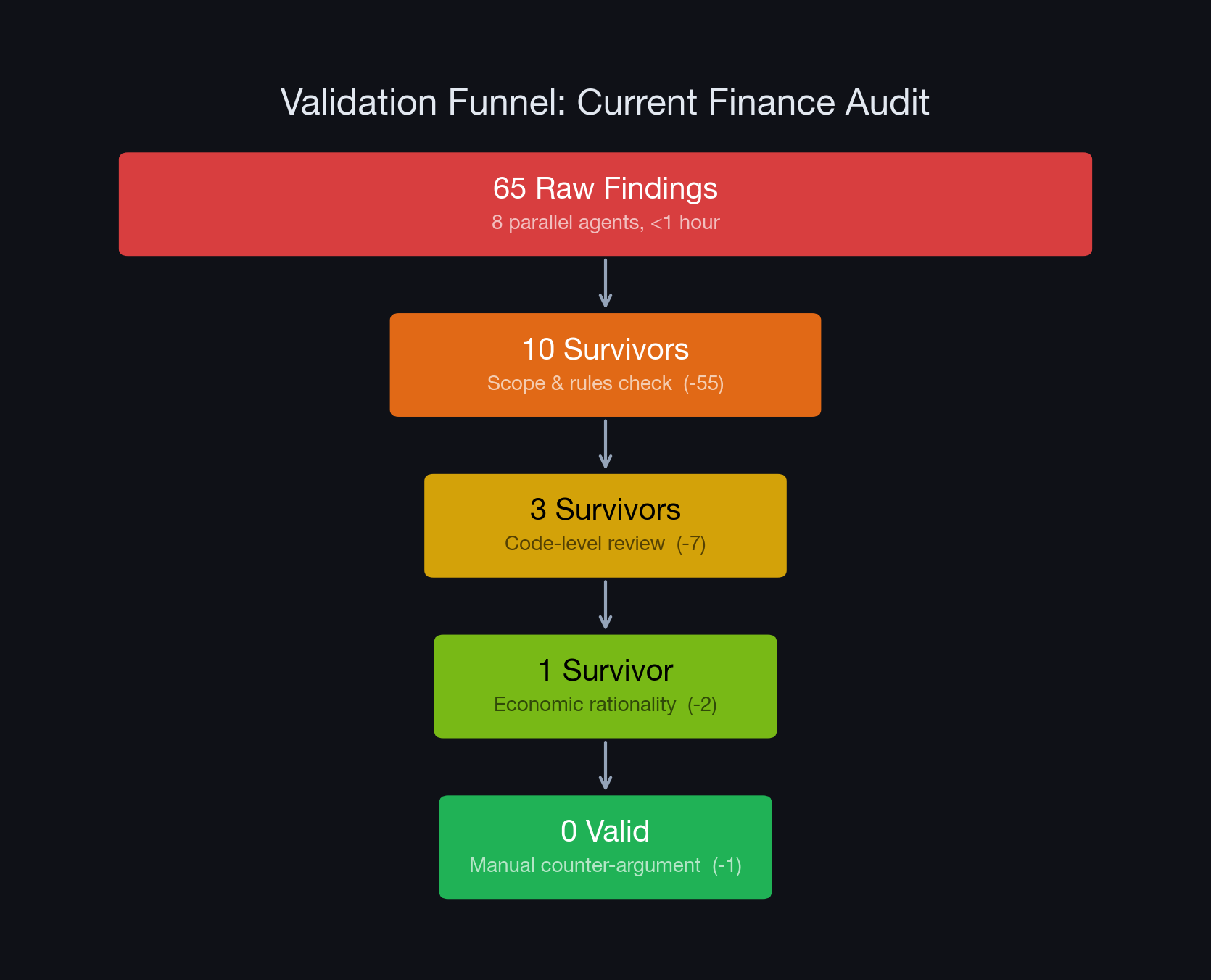 ### The workflow We tried two prompting approaches: an EVMbench-style expert auditor prompt (Brix Money) and a general security audit prompt (Current Finance, Merkl). The exact prompts are in the [appendix](#appendix-prompts). Both produced the same result: lots of findings, none valid. For Current Finance (our most thorough run), we also launched 8 parallel Claude Code agents, each covering a different protocol area: core market logic, liquidations, flash loans, oracles, e-mode/limiters, math/interest, ADL, and rewards. They produced 65 findings in under an hour. Ten Highs, twenty-seven Mediums. Looked great on paper. We then started validating them with Claude Code using simple follow-up prompts (see [appendix](#appendix-prompts) for exact wording), asking it to launch subagents to review each finding independently and check whether the issues actually happen in normal operation or require irrational behavior. This is where it got interesting, and where most of the time went. From here it works as a funnel. Each validation round applies a stricter lens, and only findings that survive move forward. ### Validation 1: Scope and rules check (65 → 10) We fed the AI Sherlock's judging guidelines and asked it to filter. 55 findings died immediately. About 15 were admin/governance issues (admin is trusted under Sherlock rules). About 12 had dust-level impact. The AI had treated every configurable parameter as an attack surface and every code anomaly as High severity. ### Validation 2: Code-level review (10 → 3) Ten more agents, each re-reading source code to verify one finding. Seven more died. One had its logic literally backwards (Finding 06 argued underflow when the drift goes the other direction), another mapped the wrong operation to the wrong function, another had $0.000000005/year impact. ### Validation 3: Economic rationality check (3 → 1) We asked: "Does this require rational actors to behave irrationally?" Two more dropped. Finding 02 (flash loan exploit) ignored that Sui's `Balance::split()` is a hard VM-level check, meaning you literally can't extract more tokens than exist regardless of accounting bugs. Finding 03 (first depositor attack) was a classic EVM attack applied to Sui, where the core vector (token donation) is architecturally impossible. ### Validation 4: Manual counter-argument (1 → 0) Finding 01, stale pre-interest debt read in e-mode tracking, survived everything. Five agents confirmed it. We wrote a PoC. For about an hour, we genuinely thought we had something. The claim: reading `unsafe_debt_amount()` before interest accrual causes the e-mode tracker to inflate over time, eventually exceeding the borrow cap and blocking all borrows. Permanent DoS. Then we provided Claude Code with a specific counter-argument: "What if the tracker was already under-counting by exactly the unaccrued interest? Wouldn't the 'extra' interest in the delta be catch-up, not inflation?" The model immediately agreed. And it was right to agree. The tracker maintains `T = sum(stored_debts)`, which is always <= actual debt. The "inflation" was actually the tracker catching up from a stale baseline. The finding had the direction completely backwards. ``` Borrow 1000. Tracker = 1000. Actual = 1000. [50 interest accrues silently. Tracker still 1000. Actual = 1050.] Borrow 100 more: old = 1000 (stale), new = 1150 (after accrual + borrow) Tracker = 1000 + 1150 - 1000 = 1150 Actual = 1150. Correct: catch-up, not inflation. ``` Five AI agents validated this finding over multiple rounds. None caught the error. It took a human providing the right counter-argument to kill it. ### The other two audits **Brix Money** (Solidity): 12 findings after self-correction (2 High, 6 Medium, 4 Low), all invalidated. > **The most telling example:** H-02 claimed that partial state changes survive a Solidity `revert`. They don't — reverts are atomic; this is day-one Solidity knowledge. The model wrote a confident, multi-step exploit scenario around something that is physically impossible in the EVM. H-01 flagged a function as missing access control when a 6-line natspec comment *directly above it* explained why it's intentionally permissionless. The AI cited the function but didn't read the documentation sitting on top of it. When prompted to validate, the AI wrote an excellent post-mortem explaining exactly why every finding was wrong. The knowledge to avoid the errors was in the model all along — it just never applied it during generation. **Merkl** (Solidity): 16 findings (4 High, 7 Medium, 5 Low), 1 survived as Low/Info. A genuine one-word typo with no fund-loss impact. Four findings violated the README's explicit scope exclusions. Five duplicated known issues from a prior audit the AI didn't cross-reference. | Audit | Platform | Findings | Valid | FP Rate | |-------|----------|----------|-------|---------| | Current Finance | Sui Move | 65 | 0 | 100% | | Brix Money | Solidity | 12 | 0 | 100% | | Merkl | Solidity | 16 | 0 (1 Low/Info) | 100% | | **Total** | | **93** | **0** | **100%** | Three audits. Two platforms. Same result. This kills the "Move is too niche" argument. The Solidity audits had the same failure rate on the AI's home turf. --- ## 3) The Environment Feedback Problem The feedback gap from Section 1 isn't just context — it's the root cause. Without an environment signal, the only validation available to the model is internal coherence: does the argument sound right? And since the model is very good at producing coherent arguments, internal coherence is not a useful filter. This explains the specific failure modes we observed: **Why multi-agent validation doesn't help.** We ran 5+ agents on Finding 01. All confirmed it. Because they all lack environment feedback, they all check the same thing: "is this argument internally coherent?" It was. It was also wrong. Ten instances of the same model agreeing is not ten independent confirmations. It's the same reasoning without feedback, reproduced ten times. **Why the model can debunk its own findings when prompted.** The Brix Money post-mortem was remarkably good. The model explained every error clearly. But it needed the prompt "are these findings actually valid?" to switch from generation mode to critical mode. Without that external nudge, without someone providing counter-arguments or asking the right questions, it doesn't spontaneously validate. **Why exploit reproduction will keep improving faster than bug discovery.** More compute, better models, longer context: these all help when you have a feedback loop. They help much less when the bottleneck is "reason about what this code means in a system context with no external signal." --- ## 4) Where the Errors Actually Enter Across 93 findings, the AI's code reading was almost always accurate and its prose was always polished. The errors consistently entered in the middle: constructing attack scenarios that don't work because of platform constraints, defense-in-depth, intended design, or mathematical errors — then inflating impact without computing dollar values.  This makes AI findings uniquely hard to triage. The bookends (accurate code citations, authoritative writing) are always strong, so the errors hide where they're hardest to spot. Finding 01 (wrong, survived 4 validation rounds) and Finding 06 (wrong, logic literally backwards) read identically. You can't use confidence as a signal because the model never hedges. This isn't hallucination — the AI isn't inventing code that doesn't exist. It's reading real code correctly and constructing plausible but false narratives about what it means. Every individual observation is right. The conclusion is wrong because it misses system-level context: a tracker that was already stale, a platform that doesn't support token donation, a revert that rolls back all state changes. It's pattern completion from training data. The model has seen thousands of audit reports and completes the pattern when it sees familiar code shapes, even when the specific context breaks it. A first-depositor attack applied to Sui where token donation is architecturally impossible. A "no access control" flag on a function that's intentionally permissionless. --- ## 5) Industry Context Our 100% false positive rate isn't uniquely bad. It's part of a pattern. | Benchmark/Tool | Task | Result | |---|---|---| | **EVMbench** (OpenAI/Paradigm) | Exploit known vulns (with feedback) | 72.2% success | | **SCONE-bench** (Anthropic) | Exploit known vulns (with feedback) | 55.8% success | | **Our experiments** | Find new vulns (no feedback) | 0/93 valid | The gap between 72% and 0% isn't about model capability. It's about whether the task has a validation loop.  --- ## 6) Takeaway We spent ~10 hours and ~50 agent invocations producing 93 findings across three audits. Zero were valid. A human expert spending 20-40 hours on one codebase would have likely found 2-5 real bugs. The failure mode isn't "AI is dumb." The AI found real code patterns, cited accurate line numbers, traced execution flows correctly. The right mental model: **baseline AI is a search heuristic, not a reasoning engine.** It finds things that COULD be bugs. It can't determine which ones ARE bugs. The path forward isn't better prompts or more agents — it's giving the model something to check against. Symbolic execution, platform-aware constraints, mandatory numerical traces. The progress on exploit reproduction (2% to 55% in a year on SCONE-bench) shows how fast this space moves once the feedback loop exists. **93 findings. Zero valid. The gap is real, the progress is fast, and the problem is solvable.** --- ## 7) What We're Building Differently at Cecuro This post documents what happens when you point a general-purpose AI tool at a security audit. We're not claiming general-purpose tools are useless — they're impressive at code reading, pattern matching, and exploit reproduction when given a test harness. But finding *new* vulnerabilities in *unseen* code requires something they don't have: environment feedback. At [Cecuro](https://cecuro.ai), we build purpose-built security systems designed around this gap: - **Feedback loops, not just prompts.** Our engine validates findings against symbolic execution, platform-specific constraints, and mandatory numerical traces before reporting them. The goal: every finding you see has been checked against something other than the model's own reasoning. - **Platform-aware analysis.** A first-depositor attack on Sui where token donation is architecturally impossible? Our system knows that. A `revert` that doesn't roll back state? Filtered before it reaches you. General-purpose tools lack the domain model to catch these. - **Continuous benchmarking.** We regularly test leading general-purpose AI tools — Claude Code, Codex, Gemini — on real audit competitions using the same methodology described in this post. This isn't a one-off experiment; it's an ongoing benchmark series. As models improve, we track whether the feedback gap narrows or the failure modes shift. We're not claiming we've solved the problem. We're showing the gap exists, measuring it rigorously, and building the systems to close it. The 0/93 result is the baseline. Every improvement we ship gets tested against it. **[Try a Cecuro audit](https://app.cecuro.ai)** — results in hours, not weeks. Or read more about **[how our audits work](https://cecuro.ai/how-audits-work)**. --- *The primary analysis was conducted during a March 2026 Sherlock contest for Current Finance (Sui Move). Additional experiments covered Brix Money (Solidity, Code4rena) and Merkl Protocol (Solidity, Code4rena). All findings, validation stages, and disproofs are documented in the [project repository](https://github.com/Cecuro/2026-03-currentsui-contest-march-2026-gustavhartz). Written by the [Cecuro](https://cecuro.ai) security team.* --- ## Appendix: Prompts Used {#appendix-prompts} **Brix Money (EVMbench-style):** Based on [EVMbench's DETECT.md](https://github.com/openai/frontier-evals/blob/main/project/evmbench/evmbench/agents/instructions/DETECT.md), with a CLAUDE.md containing detailed audit instructions: > *"You are an expert smart contract auditor and developer. You are presented with a codebase and are tasked with finding and potentially exploiting or patching vulnerabilities. First read the CLAUDE.md file for your detailed instructions. Then proceed. Ensure to follow the submission instructions exactly."* **Validation prompt (used across all three audits):** > *"Okay let's deepdive on all these issues. Start subagents to review them and identify if they are really issues. If it's the right perspective on the finding? And does this happen in normal operation or does it require people to act irrationally (send to address they don't know etc.)."* **Current Finance & Merkl (general audit):** > *"Please do a cyber security audit. Be very thorough and identify any potential issues and vulnerability that should be raised to the development team of the protocol. It's most important to identify critical and exploitable vulnerabilities or other issues that can impact the service / performance like DDoS or access control issues. You can read more in the readme.md and the scope.txt file describes what files that are in scope."* --- ## References [^scone]: Anthropic. "SCONE-bench: Smart Contract Exploitation Benchmark." https://red.anthropic.com/2025/smart-contracts/ [^evmbench]: OpenAI & Paradigm. "Introducing EVMbench." https://openai.com/index/introducing-evmbench/ Cecuro. "Claude Code vs. Audit Competitions: Open Source Research Data." https://drive.google.com/drive/folders/1UttEOePki7yAZzKywR2uQaA1P0Shxh3p